|
|
|
|
Introduction This report details the progress our group has made on our teleconferencing project. Our video-teleconferencing project consists of mainly five individual parts (extract face parameters, grab audio, send and receive audio and video data, reconstruct the face, and play audio). The sender extracts the face parameters from images taken from color camera and get the audio data from microphone at the same time. This information is then sent to the receiver(s) using unicast and multicast TCP/IP. The face is then reconstructed at the receiver’s side, and the audio data is played (synchronously).
Program Design Our system consists of two programs, a sender and a receiver. Both programs have four threads: video, audio, network, main. On the sender side, the video thread performs the feature extraction; the audio thread grabs the sound; and the network puts the data together and sends it to the receiver. The threads are synchronized by events and critical sections. The main thread is used for the main event loop and updates the user interface. The receiver’s video thread reconstructs the face using the extracted parameters; the audio thread plays back the sampled sound; and the network thread receives data from the sender and sends events to the video and audio threads when they have data that needs to be processed. We send both audio and video data in the same packet for real-time synchronization purposes. Our objective was to achieve 15+ frames per second. We sample the sound at 8KHz (8-bits), which means we need to send 533 bytes of sound data in each packet. The following is the packet structure:
The receiver creates a socket, binds it with the sender address, and begins to wait to receive the packet from the pre-determined port. For multicast type connection, all receivers and the sender have to agree on a unique multicast address. The sender and the receivers add their address to same multicast group address and they use that multicast group-address for communication.
Implementation We have implemented the system using the following hardware:
We have also used the following software:
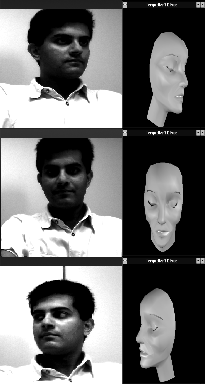
Facial Feature Extraction The facial features tracked were the following: left eye, right eye, between eyes, tip of nose, upper lip, lower lip, and chin. To track these features, a 3-CCD color camera was used along with colored dots and lipstick on the features of interest. The colored features were then segmented and classified base on color. Specifically, each feature was initialized with a "mean" color that characterized that feature’s color. The pixels in the 640 x 480 image were classified by finding the closest feature that met a user specified threshold (where "closest" means the 1-norm in RGB space). Once the features were initialized, they were tracked by finding the centroid of their pixels; new frames only looked within a certain (user specified) distance from the previous frame’s centroid. In addition to tracking the centroid, the "mean" color was updated which each new frame. The tracking of the feature’s color allowed for gradual changes in lighting due to different head poses. If a feature was lost for some reason (e.g. the person turned around or moved to fast), the system automatically tries to reinitialize the features. Double buffering of the frames was used to double the frame rate we could extract features at. Specifically, while the frame grabber was grabbing one frame , the previous frames was being processed. Two buffers were used to prevent the loss of any frames. The results of this technique were very good. All features could be tracked with very good accuracy (within a couple of pixels of hand picked points) at about 30 frames per second.
Audio Capture The audio data was captured using low-level Win32 functions and a call-back function used to implement double buffering. Double buffering of the audio data was required to prevent the loss of sound data at the sender. Once a 533 byte sound segment was sampled, the network thread was triggered (via an event), which then copied the data to another buffer (along with any available video data) and sent it off to the receiver(s). We analyzed the time intervals between the UPD packets received by the receiver (which was another computer in our lab) and were surprised to notice quite a large spread in the distribute. While the mean time between packets was about 67 ms (as we expected), there were many packets much less (some with 0-10 ms between them), as well as many much more (some with 180+). The sequence number to check if we actually lost any packets (none were in this test). The result of the above test was that we couldn’t use double buffering on the receiver side. We needed at least five, and possibly more. Our implementation uses an many buffers it needs to avoid losing sound data (sound data could be lost if two packets came less than 67 ms apart). Face Reconstruction The goal of this part is to reconstruct the parameterized face in real time. The animated face is created by using Frederic Parke’s facial model. Topologies for facial synthesis are created from explicit 3D polygons. This model consists of 508 polygons of which most of them represent the face flesh and about 40 represent mouth and teeth. To add a level of dynamic realism, the eyelids can be created and animated as well. The parametric facial model is animated and creates expressions by specifying the set of parameter values such as head orientation, lips movement, jaw movement, etc. These parameters are extracted by facial feature extraction module at the sender side. Once the features are extracted, the sender automatically computes the parameter set and send them via the network to animate the facial model at the receiver side. To implement this real-time facial reconstruction, we use OpenGL for WindowNT and a 3D graphic accelerator (Matrox Millienium). The face polygons are bound with the different materials for different facial parts (flesh, lips, eyelash, etc). Then they are rendered and shaded to make it more realistic. In addition, the double buffering is performed. While a buffer is displayed, the other one is being drawn. When the drawing is complete, they are swapped. This technique makes the animation more smooth. Eventually, we achieved about 4-16 frames per second depends on the face display window size. When the window size is about 2x2 inches, we get about 16 frames per second.
Conclusions We have designed and implemented a teleconferencing system that using feature extraction for human faces to greatly reduce the bandwidth needed. By making some key simplifications (e.g. using color to track features of interest), we were able to develop a system that runs in real-time. The reconstructed face shows head pose and the shape of the mouth, which is synchronized with the voice data. Extensions such as tracking the eyebrows, eyes, and other contours of the face would further enhance the system’s realism. |